040 — CUBA-PING
Abstract
nb025–nb038 characterise PING in the conductance-based regime, where every synapse has an exponential filter at or . This entry asks whether current-based (CUBA) PING with instant synapses — no synaptic filtering at all — still produces the gamma dynamics and can be trained.
Methods
LIF E and I populations with the same wiring as nb025’s COBA-PING but with no synaptic state: every presynaptic spike at contributes its weight to the postsynaptic current at and is gone by .
- , , , ms, ms.
- Membrane: ms, , , hard reset to on spike, . is floored at after each step (membrane can’t fall below the dominant ion’s reversal potential). No refractory period — after reset the cell is free to fire on the next step; the only mechanisms limiting firing rate are membrane decay back to threshold and (in the PING arm) the I-loop suppression.
- Weights: , , both clamped non-negative; is 95% sparse with entries.
Both arms — full PING and the E-only ablation — go through oscilloscope train --model cuba-ping ... and --model cuba-noping ... respectively; recipe, optimiser, surrogate gradient, TBPTT window, batching, and seed all match. The output layer is a non-spiking LIF integrator ( ms) whose time-averaged membrane is the logits — so silent hidden activity gives a flat output and no class signal. The hidden layer is forced to spike for the readout to carry any information.
Results
Untrained dynamics
Fixed weights, no training. Spatially uniform Poisson input at 80 Hz per channel for the full 200 ms window.
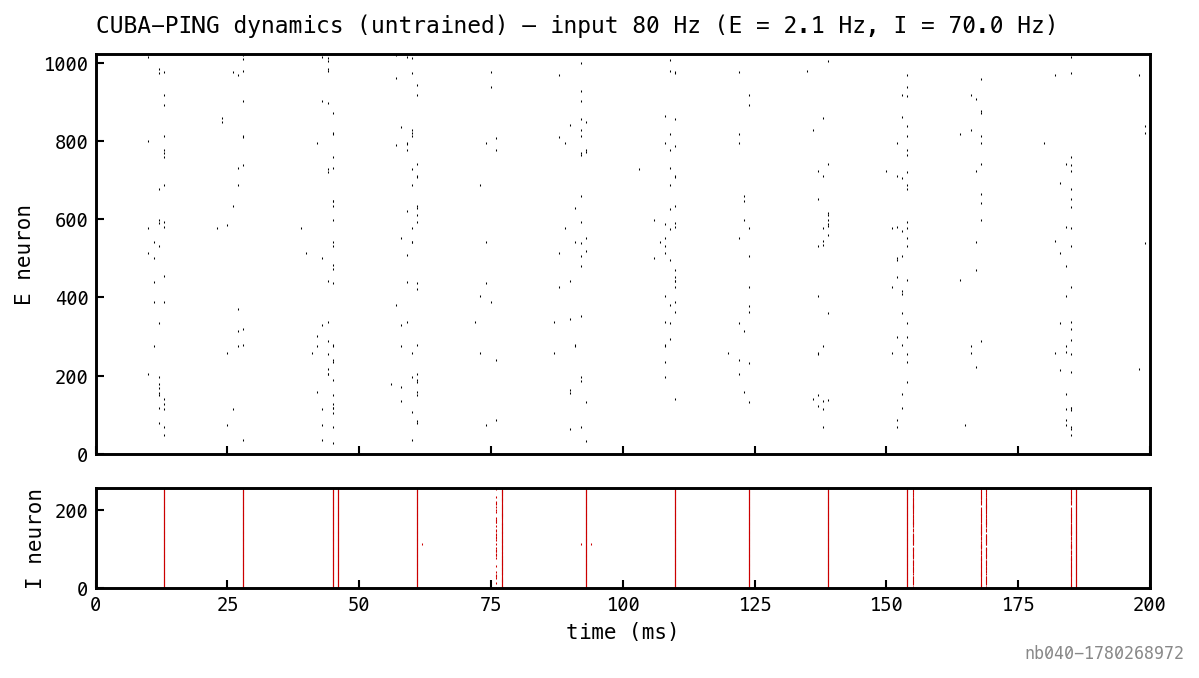
Spike raster from one trial with fixed random weights and uniform 80 Hz Poisson input on every channel. E above (black), I below (red). I shows narrow synchronous bursts at gamma cadence; E bursts immediately precede each I burst.
Recruitment threshold, inhibitory clamp on the E rate, periodic E→I bursts — the architectural signatures of PING survive without any synaptic filter. The cycle period is set jointly by and the time it takes the input drive to push enough E cells back above threshold for the next round.
Training CUBA-PING
and trainable, frozen and . Surrogate-gradient BPTT on Poisson-encoded MNIST. Adam at lr , batch 64, mem-mean output readout, TBPTT window . The window is load-bearing — full BPTT diverges (Section BPTT stability below).
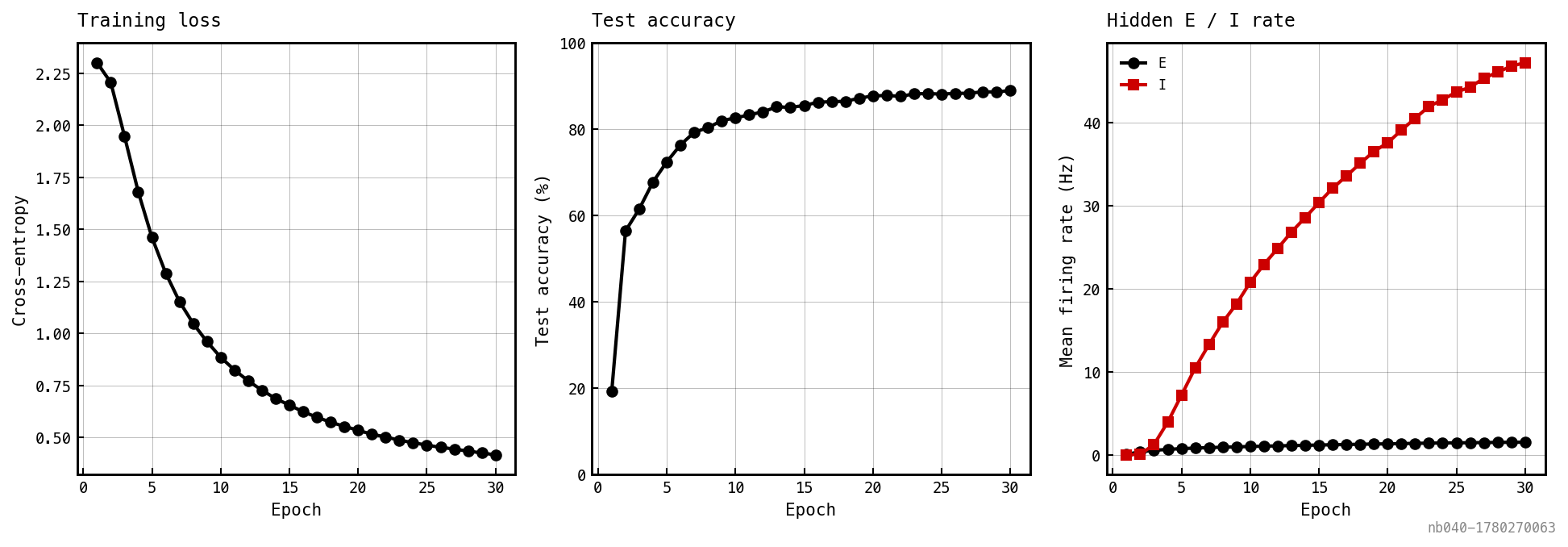
Cross-entropy loss (left), test accuracy (middle), and mean hidden E (black) / I (red) rates (right). The I-loop suppresses E to ≈1 Hz while the readout drives accuracy upward. Headline numbers above reflect the run that produced these figures.
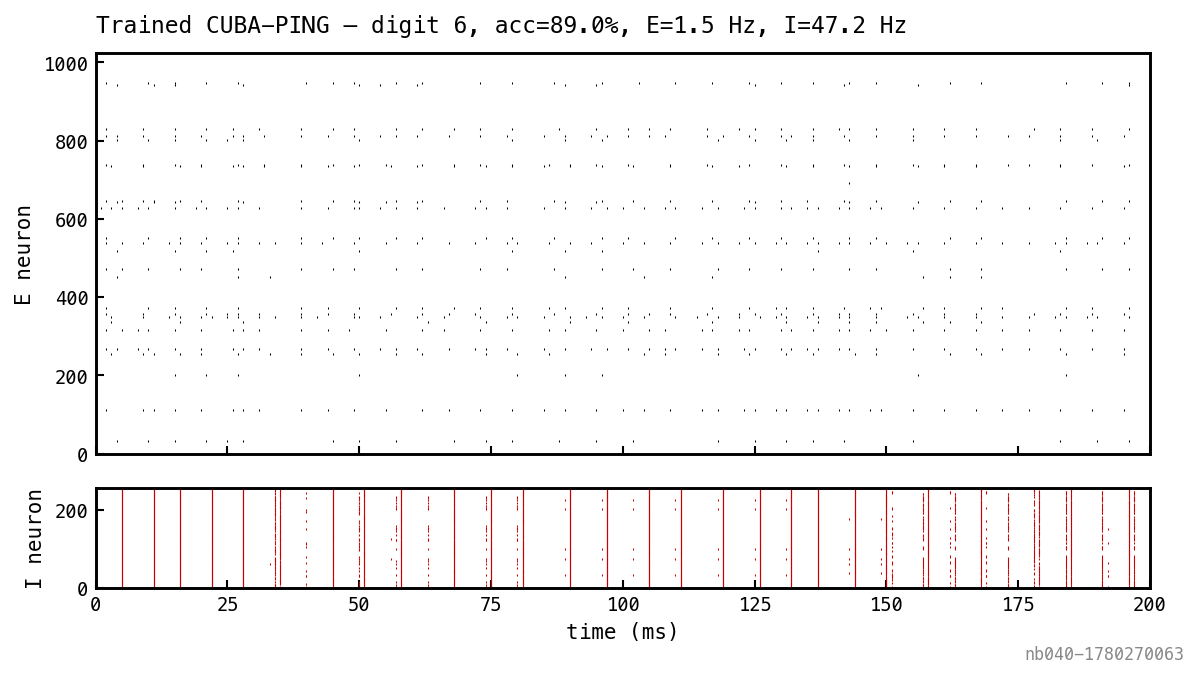
One MNIST test sample replayed on the trained network. Untrained PING dynamics (Figure 1) survive — E spikes are sparse and digit-selective; I bursts at gamma cadence.
CUBA-no-PING ablation
The interesting question is why CUBA-PING ends up at sub-Hz E rates. Two candidates:
- The I-loop clamps the rate. Inhibitory feedback suppresses E whenever it gets recruited; the optimiser finds a sparse-spike solution. PING is necessary.
- The mem-mean readout doesn’t need spikes. A continuous membrane readout can classify from patterns directly. PING is incidental — any CUBA LIF stack would do.
The control: a CUBA no-PING network (E-only, no , no , no I population), same recipe as above.
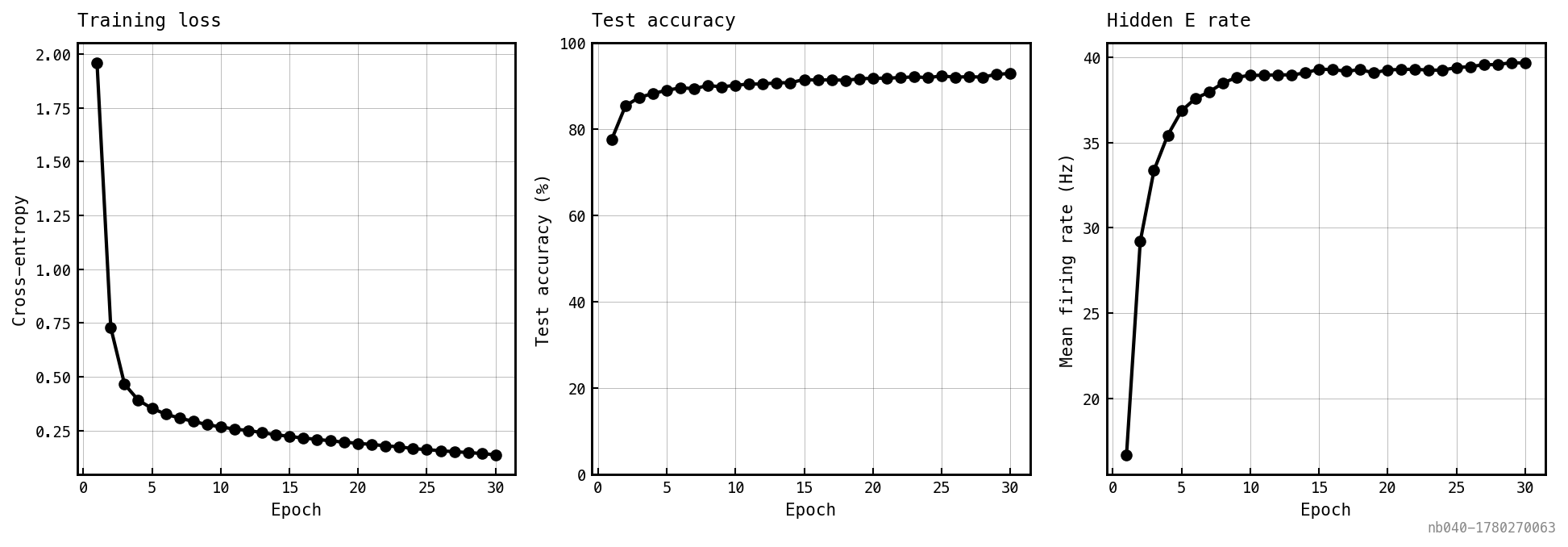
Same axes as Figure 2 minus the I-loop. The E rate climbs immediately into the tens of Hz; accuracy converges within a handful of epochs.
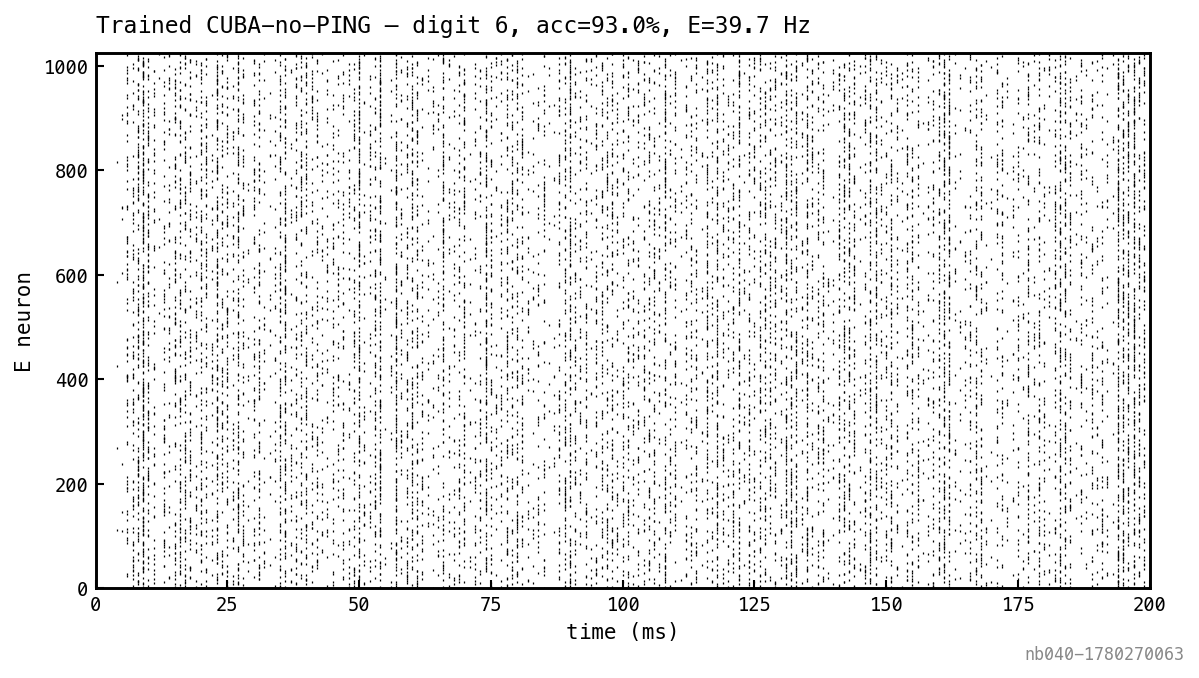
E spike raster for one MNIST test trial after training. No I population to render. Compare to Figure 3 — the trained network is dense-spiking across the trial rather than sparsely bursting.
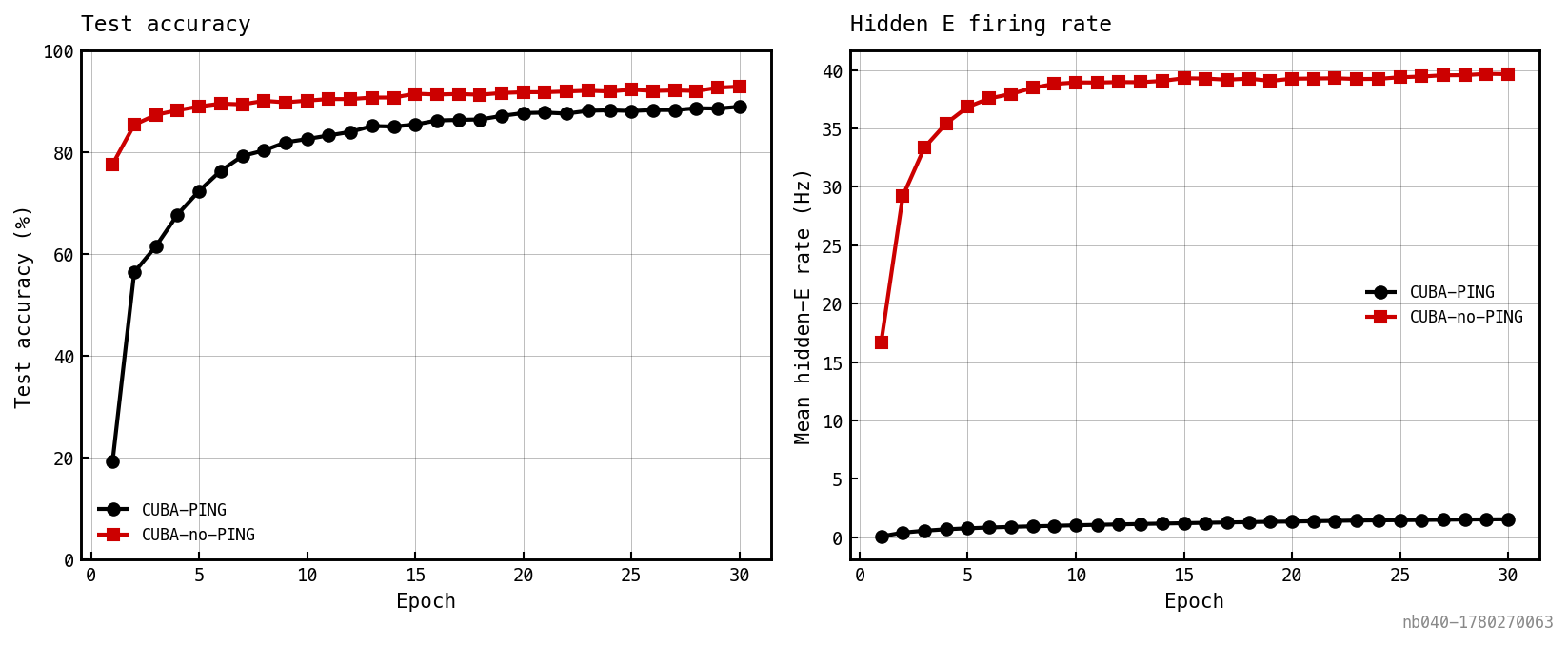
Black: CUBA-PING. Red: CUBA-no-PING. The rate curves diverge by an order of magnitude; the accuracy gap is bounded.
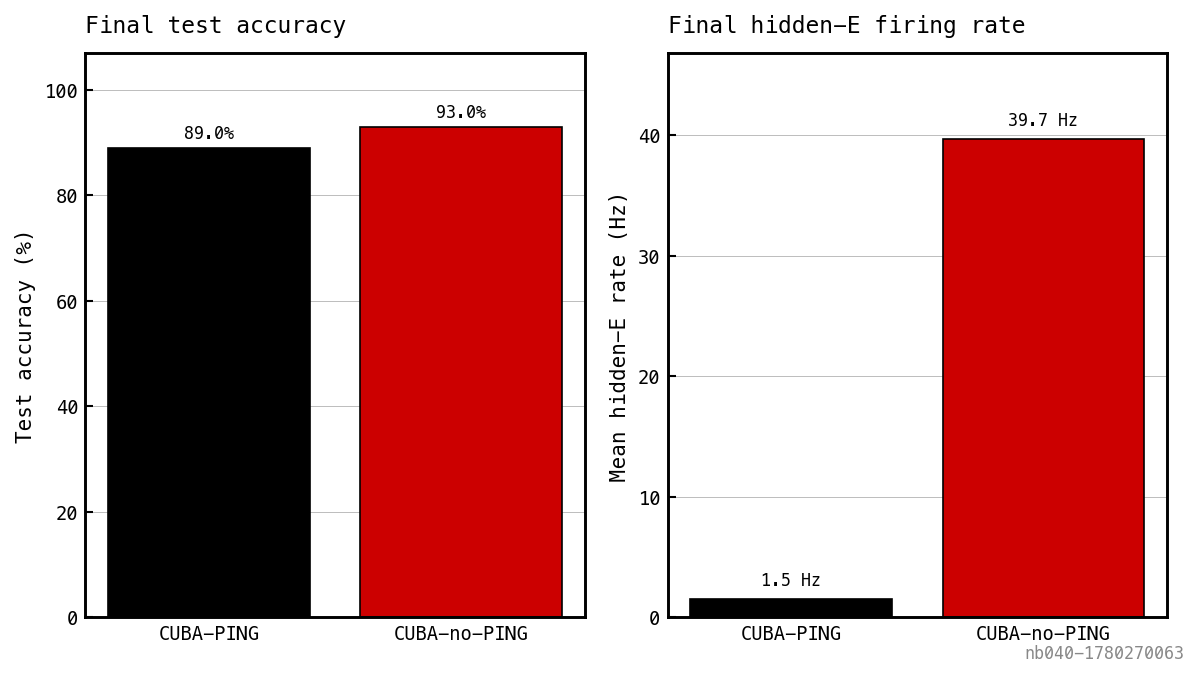
Final test accuracy (left) and mean hidden-E firing rate (right) at the end of training. The same axes as Figure 6 collapsed to single numbers — the rate-accuracy trade in headline form.
Both effects of the I-loop show up cleanly:
- The rate clamp is real and strong. Removing the I-loop lets the E rate climb into the tens of Hz — biologically high but within the snnTorch / rate-coded SNN regime. The I-loop in place holds the rate near 1 Hz: an order-of-magnitude sparsification with no regulariser.
- The sparsification has a real but bounded accuracy cost. Roughly 4 pp at large tier. The output-LIF readout integrates spike events, so suppressing E spikes throttles the output membrane response; the network still has enough integrated signal to classify, just less than the dense-spike control.
This is the same tradeoff the COBA-PING baselines in nb025 Figure 5 walk via the spike-budget term — except CUBA-PING walks it by the architectural inhibitory clamp rather than by an explicit penalty.
BPTT stability
The single design choice in the training section that takes some justification is the TBPTT window. With the network trains; with (full BPTT) gradients overflow to NaN within the first batch.
The recurrent Jacobian
The loss depends on via the output-LIF integrator. By the chain rule the gradient on accumulates at every step, and that backward signal routes through s_E and s_I via the I-loop even though the forward readout doesn’t.
One E→I→E round trip:
Four Jacobian links: surrogate at E (bounded by , the surrogate slope), E→I drive ( with operator norm ), surrogate at I (bounded by ), I→E suppression ( with operator norm ). Multiplying:
For random matrices with entries the spectral norm is well-approximated by :
- , at , shape or transpose: .
- .
Just under unity at this recipe — but with moderate spectral slack the per-cycle factor exceeds 1 and growth begins. Over steps the compound overflows float32 well before the trial ends, so full-horizon BPTT is unreliable in practice.
Why truncated BPTT works
TBPTT with window caps the per-cycle compound to round trips instead of . The per-step factor raised to is finite and well within float32. More importantly, the consistently-signed suppression signal is now summed over steps instead of , so its magnitude is comparable to the readout signal and the optimiser sees a balanced gradient.
The cost is bias. TBPTT computes the gradient as if each window were independent. This is wrong — at step 10 really does depend on at step 1 via membrane decay. For 200 ms MNIST trials this bias is negligible; for sequence tasks with genuine long-range structure (language modelling, sequence MNIST), TBPTT would underestimate long-range gradients and systematically miss those features. Calling it “truncated” is a bit unfair — the truncation isn’t a bug, it’s the regulariser that lets you train at all. Local-BPTT or gradient horizon limit would be a more honest name.
Discussion
The instant-synapse CUBA-PING has the right dynamics without any synaptic filtering (Figure 1), is trainable when (a) the readout is an output-LIF mem-mean that requires hidden spikes to flow and (b) the BPTT horizon is limited to a few times , and is ablation-checked: removing the I-loop raises the E rate by an order of magnitude at a bounded ≈4 pp accuracy cost. Both arms go through the same oscilloscope code path, so the only difference between Figures 2/3 and Figures 4/5 is the I population’s presence.
Next steps
- Scale to full MNIST. Training loss is still decreasing at the end of the medium-tier run, so the operating point is not yet converged. Full MNIST + more epochs should close the gap to the COBA-PING baselines.
- Add an explicit like nb025’s, exposing a knob that lets you slide along the rate–accuracy frontier on top of what the architecture already gives.
- Replace TBPTT with a principled stabiliser — spectral normalisation of / , or a Jacobian-norm regulariser — that lets full-horizon BPTT through and closes the COBA-PING gap from below.
- Add a refractory window ( ms for E, ms for I, matching the COBANet baselines). The current model has none, which gives every cell an unbounded firing-rate ceiling and likely contributes to the no-PING control’s ≈70 Hz E rate. With refractory in place that ceiling drops to Hz for E cells; the no-PING upper rate would compress, narrowing the rate gap to the PING arm without changing the qualitative comparison.