049 — Gradient descent prunes PING via Dale's-law clamping (trains)
Abstract
In nb025 the recurrent inhibitory weights are frozen at biophysical values — the gamma loop is treated as anatomy, not as something training can touch. If we unfreeze them, does Adam rediscover the same loop? No. The frozen control trains to canonical PING ( Hz, Hz, Hz, 86% test accuracy). Every trainable condition — whether started at canonical PING values, at zero, or at 10% of canonical — collapses to dense E firing with the I population silent, at 88% accuracy. The mechanism is Dale’s-law-mediated pruning: Adam drives most entries below zero, the forward-pass clamp turns them into structural zeros, and the loop is gone. PING is a structural prior the architecture imposes through the freeze, not one gradient descent recovers on its own.
Methods
Architecture. excitatory, inhibitory, mem-mean readout, Dale’s law enforced. Hyperparameters match the nb025 PING baseline: Adam at lr , batch 256, surrogate slope 1, at 95% sparsity, gradient norm clipped to 1.0, ms, ms, no firing-rate regulariser.
Sweep. Four conditions × three seeds (42, 43, 44) on the medium tier (1600 train / 400 test MNIST, 100 epochs). Only the initial and the trainable-or-not flags vary across conditions.
| Condition | init | Trainable? |
|---|---|---|
| frozen_ping (control) | canonical biophysical | no |
| trainable_ping_init | canonical biophysical | yes |
| trainable_zero_init | (COBA-equivalent start) | yes |
| trainable_small_init | canonical | yes |
Canonical biophysical means μS, μS at , fan-in-normalised — so the trainer reports per-edge means of ≈ 0.0010 and ≈ 0.0078.
Results
Each condition gets two paired figures: a diagnostic card (training trajectories on top, final E PSD bottom-left, single-trial raster bottom-right) and a weight-distribution card (histograms of and entries, init outline vs trained fill). The histograms show effective values — stored entries with are clamped to zero before histogramming, so the Dale’s-law-pruned majority piles up in the first bin and surviving entries form the right-hand tail. Legends report the post-clamp mean and the pruned fraction.
Frozen PING (control)
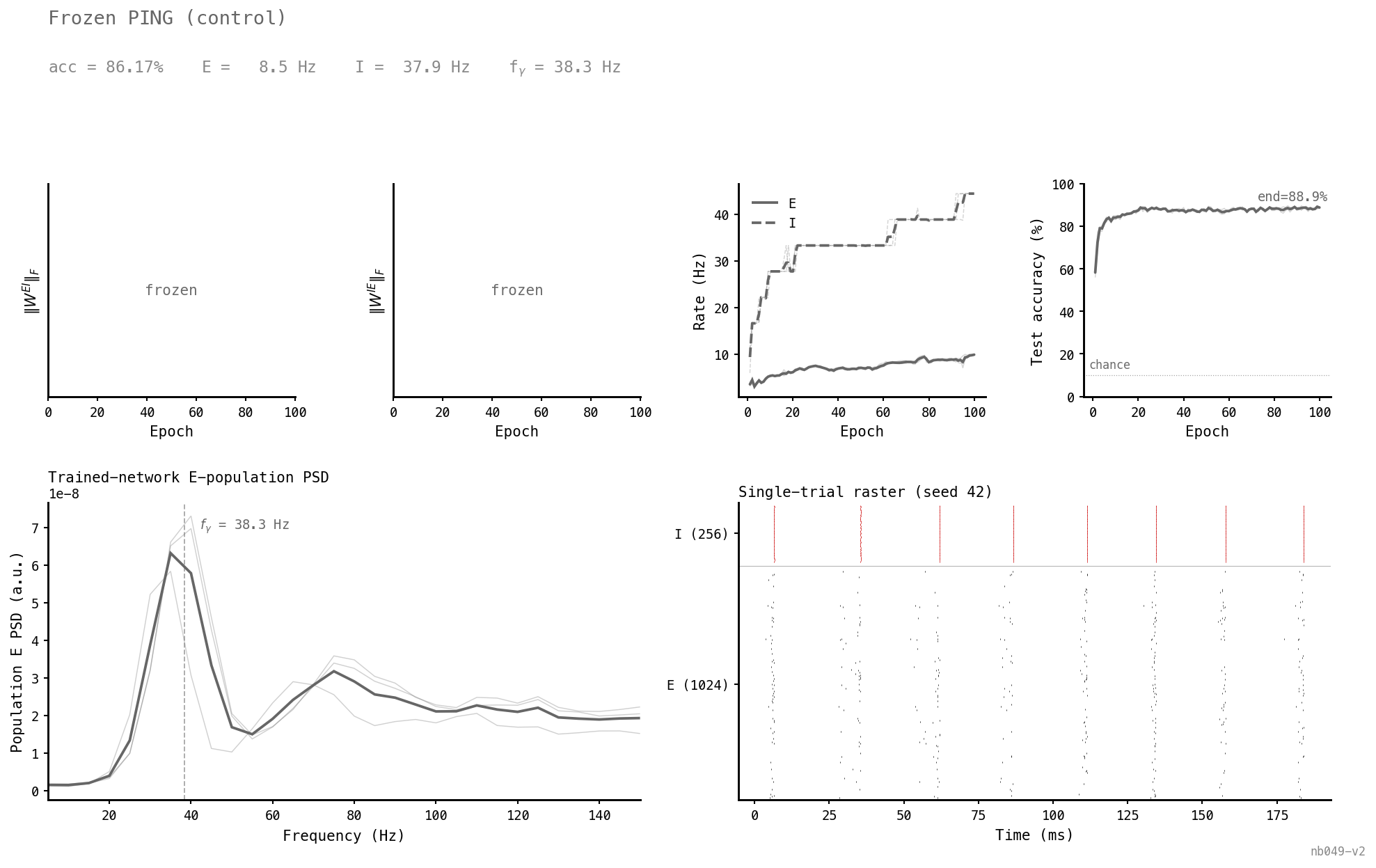
Recurrent weights stay at canonical. E and I rates settle at ≈ 8.5 / 38 Hz, the PSD has a clean gamma peak at 38 Hz, the raster shows cycle-locked bursts. 86.2% test accuracy. This is the reference for what “PING is on” looks like.
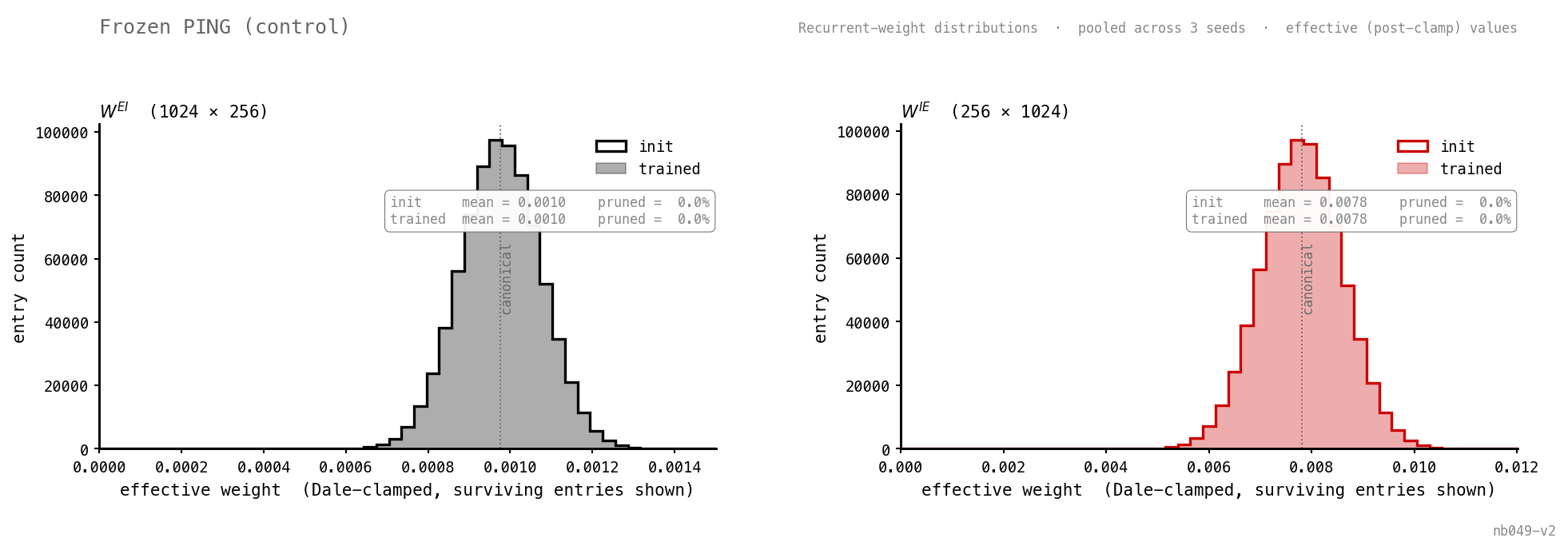
Init and trained distributions overlap exactly. The sanity check: nothing about the recurrent loop moves.
Trainable, PING initialisation
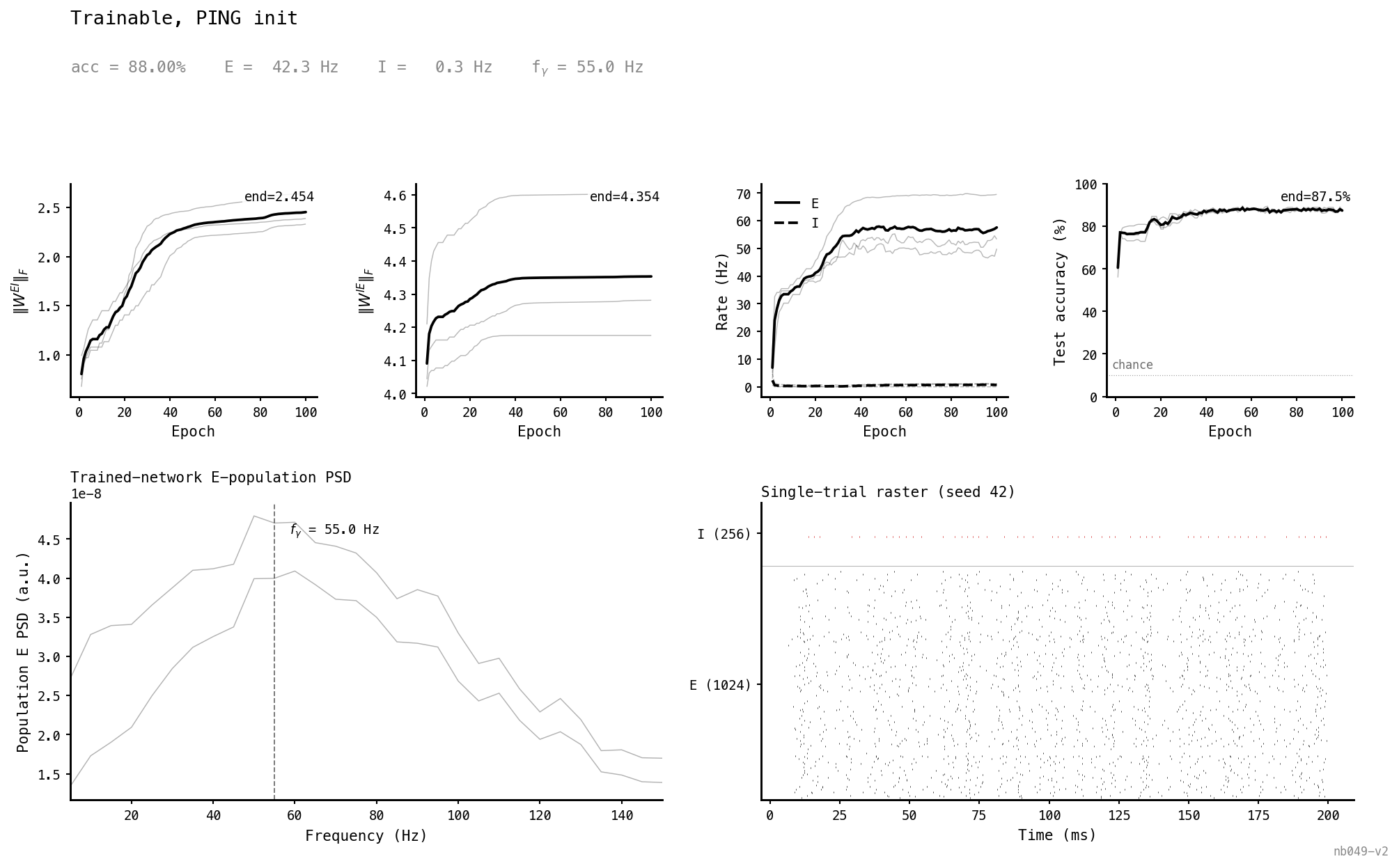
Start the trainable recurrent matrices at the canonical PING values and let them go. Within 15 epochs the I population is silent, E saturates near 42 Hz, the gamma peak drifts up to ≈ 55 Hz, and the raster shows dense asynchronous E firing. 88.0% accuracy — about 2 pp above the frozen control.
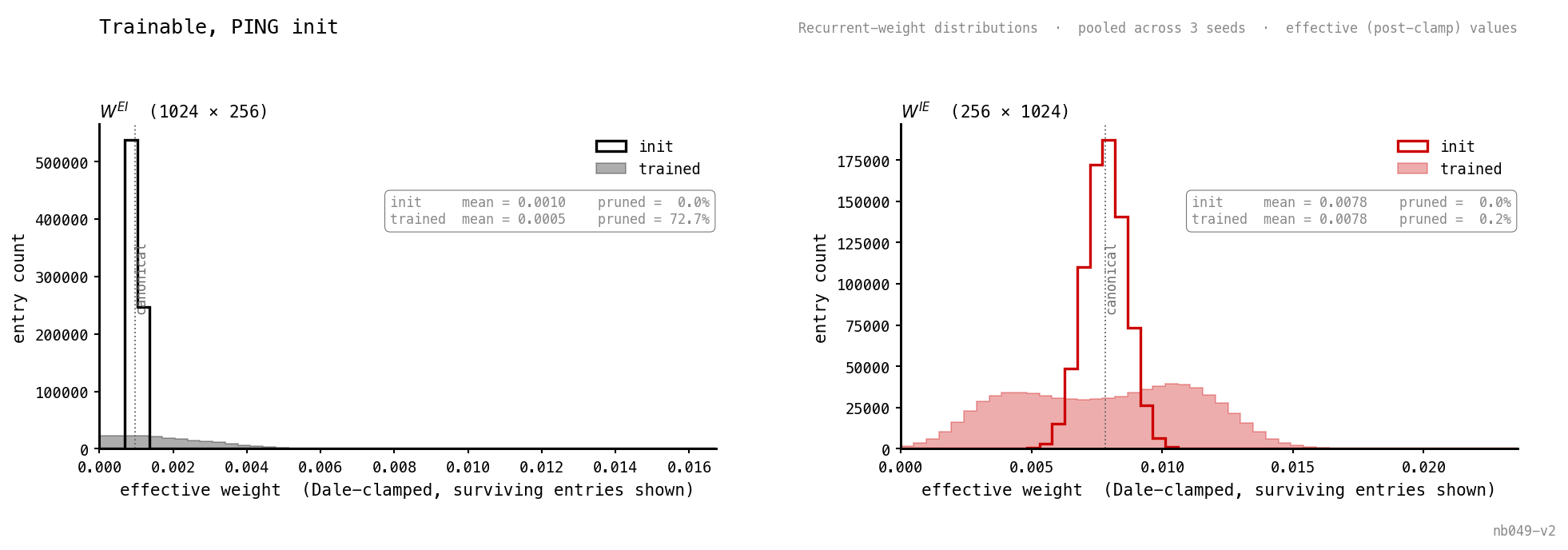
Why the loop dies: 73% of entries are pruned (Adam pushed them below zero, the forward-pass clamp made them structural zeros). The surviving 27% grew, but the post-clamp mean dropped to 0.0005, below the init’s 0.0010. barely moves. Most I cells lose their drive, the gamma shunt that paces E firing vanishes.
Trainable, zero initialisation
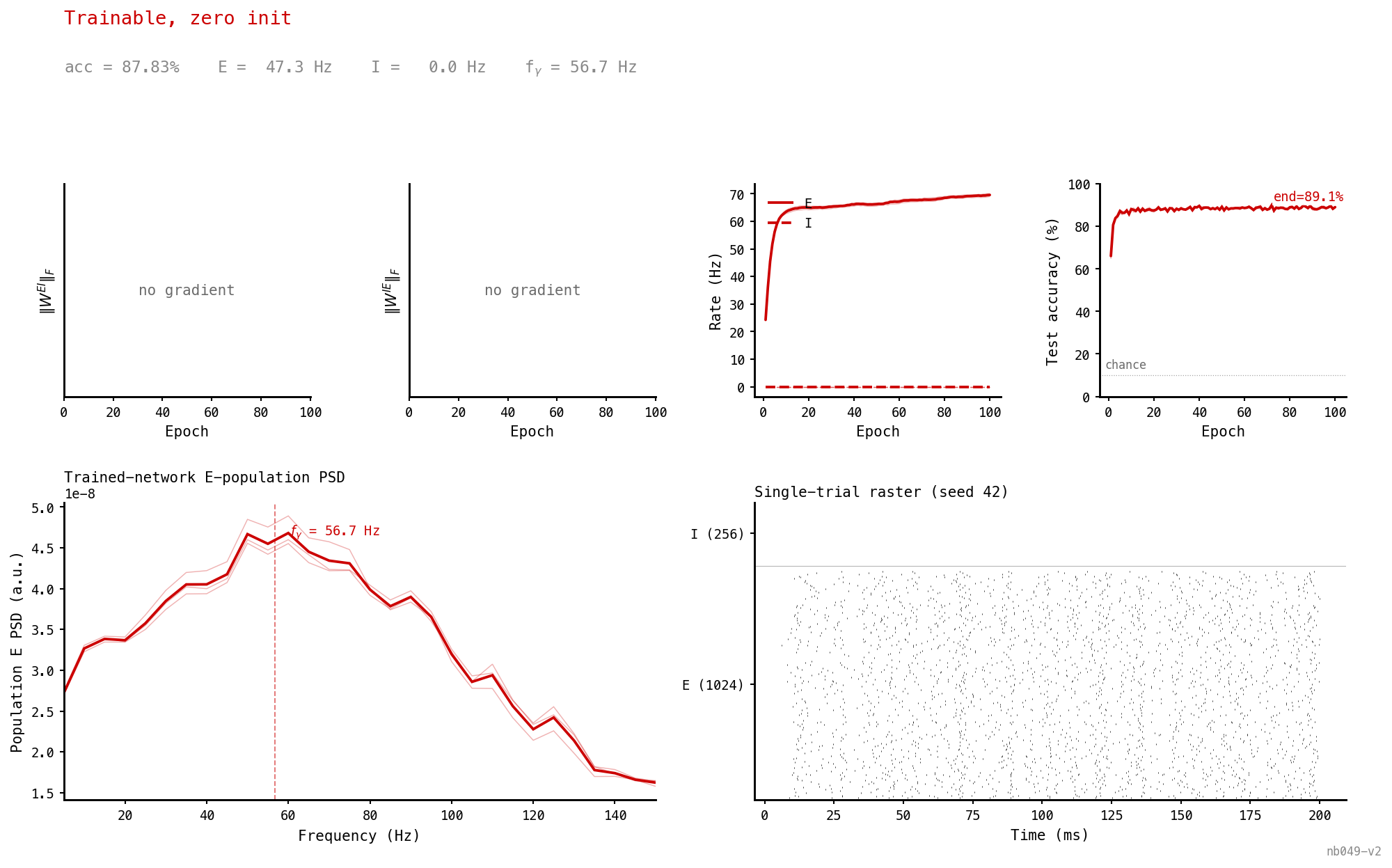
Start the loop disabled. Gradient descent never reactivates it: the recurrent weights stay at zero throughout, the network runs as plain COBA, E fires densely, I is silent. Accuracy still 87.8% — within 0.2 pp of the trainable-PING-init case. From a cold start, there’s no gradient path back to PING.
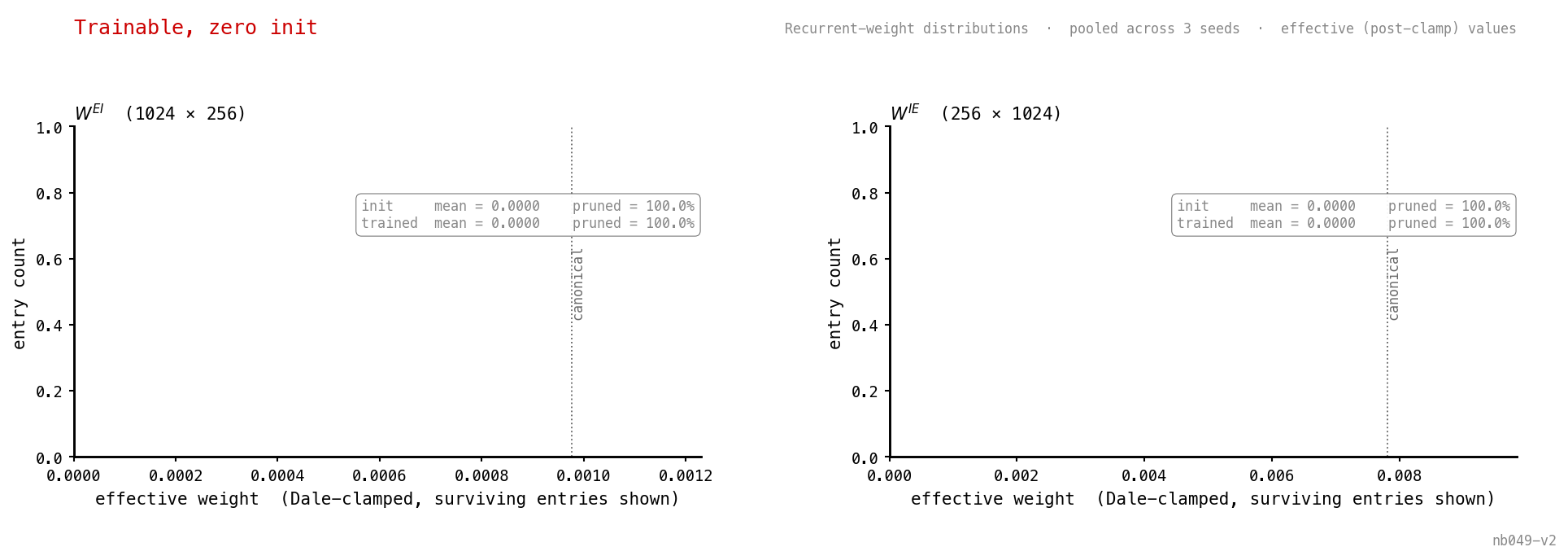
Both panels are a single spike at zero. No gradient flows back into a disabled loop, so nothing moves.
Trainable, small initialisation
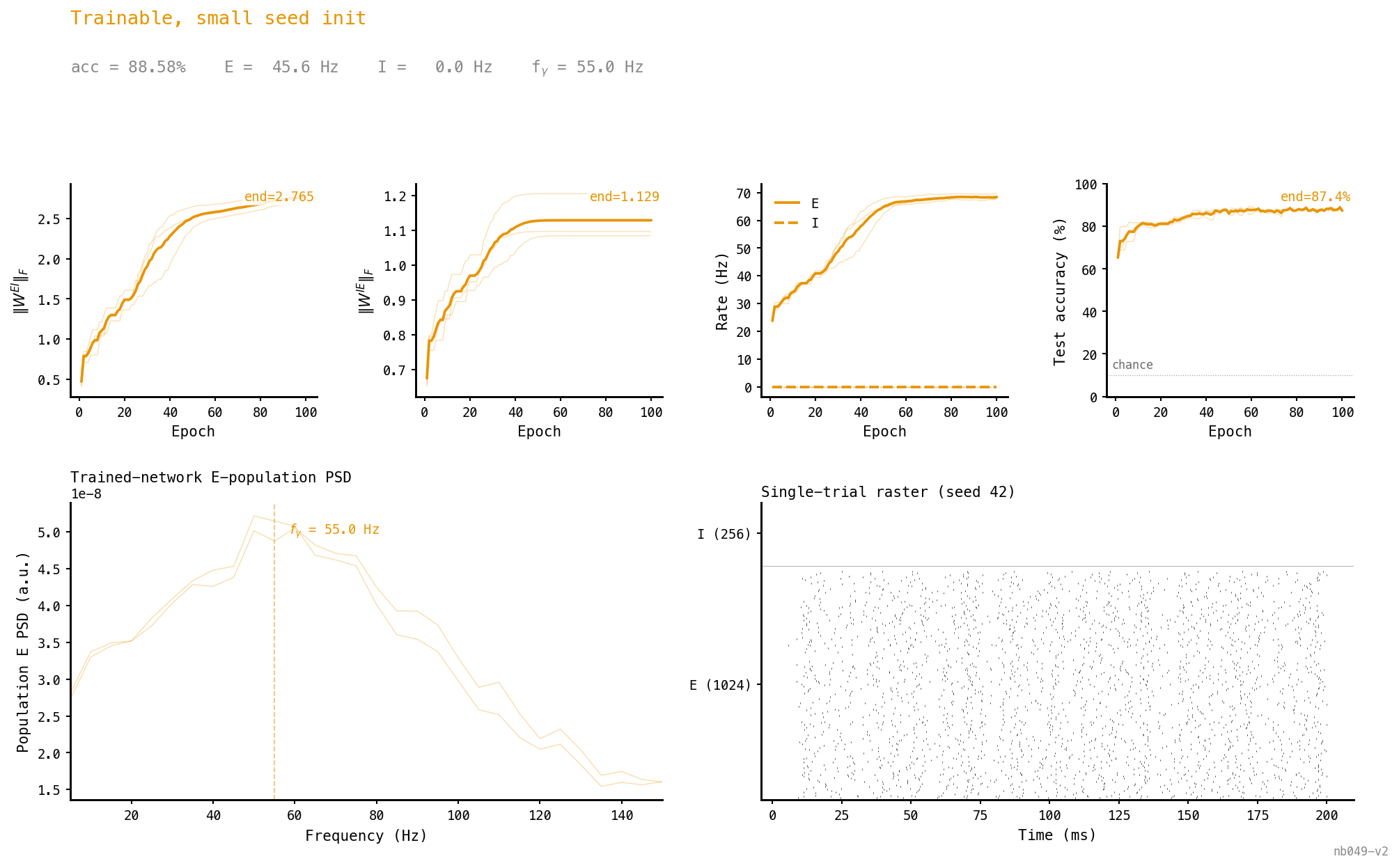
Start at 1/10 canonical so there’s a small but non-zero gradient signal in the loop. Same endpoint as the canonical-init case: dense E, silent I, 88.6% accuracy.
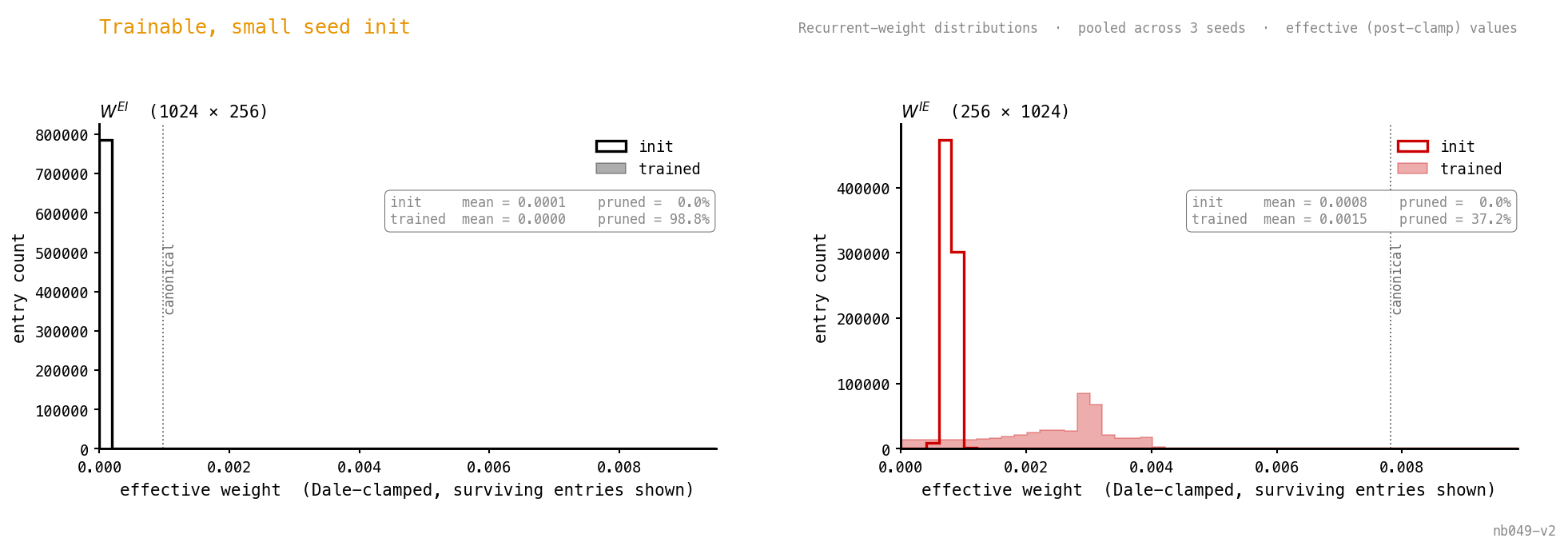
Sharper version of Figure 4: 99% of pruned and 37% of pruned. The few survivors grow, but the population-level effect is loop dismantling.
At-a-glance comparison (mean across three seeds)
| Condition | Acc (%) | (Hz) | (Hz) | (Hz) | pruned / eff. mean | pruned / eff. mean |
|---|---|---|---|---|---|---|
| frozen_ping | 86.2 | 8.5 | 37.9 | 38 | 0% / 0.0010 | 0% / 0.0078 |
| trainable_ping_init | 88.0 | 42.3 | 0.3 | 55 | 73% / 0.0005 | 0% / 0.0078 |
| trainable_zero_init | 87.8 | 47.3 | 0 | 57 | 100% / 0 | 100% / 0 |
| trainable_small_init | 88.6 | 45.6 | 0 | 55 | 99% / 0.00002 | 37% / 0.0015 |
The frozen control reaches healthy PING; every trainable condition reaches the same dense-E / silent-I attractor at ≈ 88% accuracy — about 2 pp above the control. Starting state doesn’t matter, only whether the loop is allowed to train.
Discussion
The mechanism, in one sentence: Adam drives most entries below zero and Dale’s law clamps them to structural zeros, so the loop loses its drive to I and the gamma shunt that paces E firing disappears.
The naïve view — ” grew, so the loop should be stronger” — is what makes the result look paradoxical at first. The Frobenius mean of the absolute stored parameters does grow, because the negative-stored pruned entries contribute their absolute values to that average. But that’s not what the network sees: the forward pass clamps them, the effective mean drops below init, and the dynamics behave as if the matrix has been sparsified to ≈ 16% of its connectivity with a strong-but-rare survivor pattern. The few I cells still receiving drive can’t gate the whole E population.
This makes the rate-floor framing in ar009 / ar010 more honest about its scope. The mechanism requires the gamma cycle, which requires the loop to remain biophysically scaled. MNIST does not select for that — if anything it selects against it, since the dense-fire COBA attractor scores 2 pp higher. The argument is therefore “freezing the loop gives a rate-bounded sparse code that streams cleanly”, not “the network would find this regime on its own”. Whether a streaming or continuous-input task changes the calculus — by making the readout pay for dense-fire saturation — is the natural follow-up, started by nb048.
Two caveats:
- Two cells NaN’d late in training (trainable_ping_init seed 42, trainable_small_init seed 44). Their pre-NaN trajectories matched the surviving seeds; final-state numbers average the non-NaN cells. The collapse story doesn’t depend on them.
- MNIST is thin. One-shot 200-ms classification with a permissive linear readout doesn’t reward temporal sparseness. A task that does is the cleanest follow-up.
Next steps
- Streaming task with trainable loop. Run this experiment on the streaming-MNIST protocol from nb048 — does the dense-fire attractor still win when the readout is sensitive to over-saturation?
- 2D init sweep. Sample initial means across a plane and map the attractor basins.
- trainability. Does changing the I time constant shift which attractor wins?
- Anti-pruning regulariser. Penalise either canonical or low gamma-band PSD and ask how strong the penalty has to be before Adam stops dismantling the loop.